
In modern distributed database environments, it has become
clear that the weak link, from a performance stand point, is the IO
subsystem. RAM and CPU speeds and
reached impressive performance levels but the data access levels have not kept
up with those of RAM or CPU.
This represents a real problem for users of databases and a lost opportunity to keep database management systems, as we know them, a viable tool in a world of exponential data growth. People simply will not put up with less than optimal performance in today’s fast pace digital world.
The engineers at Microsoft recognized this and introduced
the column store index. The column store
index has proven to be incredibly fast for a high percentage of data warehouse
queries specifically those targeting large fact tables which are where all the
juicy meat is in a data warehouse.
Row Store and Column Store
A traditional B-tree structure in clustered and non-clustered indexes is based on a physical layout of data called a row store. Simply put data is stored in data pages in your standard spreadsheet type of rows. A column store turns this all on its head and stores data in a column oriented layout.
Here is a simple graphic of the differences: (thank you http://arxtecture.com/ for this graphic)
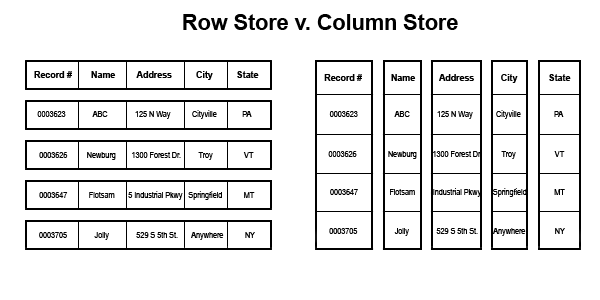
Read what you need
This all seems like a simple enough concept but when you examine what this difference in physical layout really means performance it is actually quite amazing.
If you are querying only a subset of the data from a table
and you specify the individual columns then you pull out only the requested
data into memory and leave the rest behind.
This is a huge IO savings.
Compression
Also, Microsoft used a very aggressive compression technology from Vertipaq and this technology is hugely effective when using a column based physical layout. For example: suppose you have a column such as gender and you only have a handful of possible values. This type of column that has very low selectivity is an ideal candidate for a high degree of compression. If you had a fact table with many rows like this and you applied a highly aggressive compression ratio to it you again are decreasing the IO and increasing the performance times.
Ideal for data warehouse fact tables
In today’s modern data warehouses that use traditional star and snow flake schemas, it is not uncommon for fact tables to be incredibly large. In order to provide a high level of aggregation of the more granular fact details, queries against fact tables are usually range based and implement a lot of scanning, sorting and aggregating of the data. If the data is stored in a column based physical layout then the savings of IO that come from there being more necessary data per page read into memory, more efficient levels of compression and better memory buffer usage really begins to add up fast. These benefits combined with the new batch model that the query optimizer offers can increase performance by up to 10x and sometimes up to 100x according to a Microsoft white paper called ‘Enhancements to SQL Server Column Stores.’
There are of course limitations and best practices that
should be considered as well so be sure to look into those before you go changing
all your indexes into column store indexes.
Thanks for reading,
SQL Canuck
No comments:
Post a Comment